library(pacman)
p_load(
ggplot2,
dplyr,
wesanderson,
ggtext,
corrplot,
RColorBrewer,
ggsignif,
ggdist,
ggpubr,
metafor,
forestplot,
plotly,
htmlwidgets,
fGarch,
install = TRUE
)Gráficos en R (vol. II)
R
Visualización
ggplot2
Matrices de correlación, gráficos de barras con intervalos de confianza, violin plots, cómo combinar figuras, forest plots para meta-análisis y gráficos interactivos con plotly.
(realizado junto a Eva Moreno Bella)
En el volumen I vimos la lógica de ggplot2 y cómo construir un gráfico capa a capa. Aquí ampliamos el repertorio: matrices de correlación, gráficos de barras con intervalos de confianza, violin plots, cómo combinar varios gráficos en una figura, forest plots para meta-análisis y, por último, cómo hacer cualquier gráfico de ggplot2 interactivo con una sola línea.
0. Paquetes y datos
set.seed(1)
# Cuatro grupos para comparaciones
data_1 <- dplyr::tibble(group = "group a",
data_col = fGarch::rsnorm(50, mean = 3.5, sd = 1, xi = 10))
data_2 <- dplyr::tibble(group = "group b",
data_col = rnorm(15, mean = 4.5, sd = 1.0))
data_3 <- dplyr::tibble(group = "group c",
data_col = rnorm(20, mean = 4.6, sd = 0.8))
data_4 <- dplyr::tibble(group = "group d",
data_col = rnorm(4, mean = 4.0, sd = 0.5))
datos4g <- rbind(data_1, data_2, data_3, data_4)
datos4g$group <- factor(datos4g$group)1. Matrices de correlación
1.1. Preparar los datos
Usamos el dataset iris que viene con R. Quitamos la variable Species porque corrplot necesita una matriz solo con variables numéricas:
datacor <- iris %>% mutate(Species = NULL)
matcor <- cor(datacor)1.2. Corrplot básico
corrplot(matcor, tl.col = "black", tl.cex = 1.2)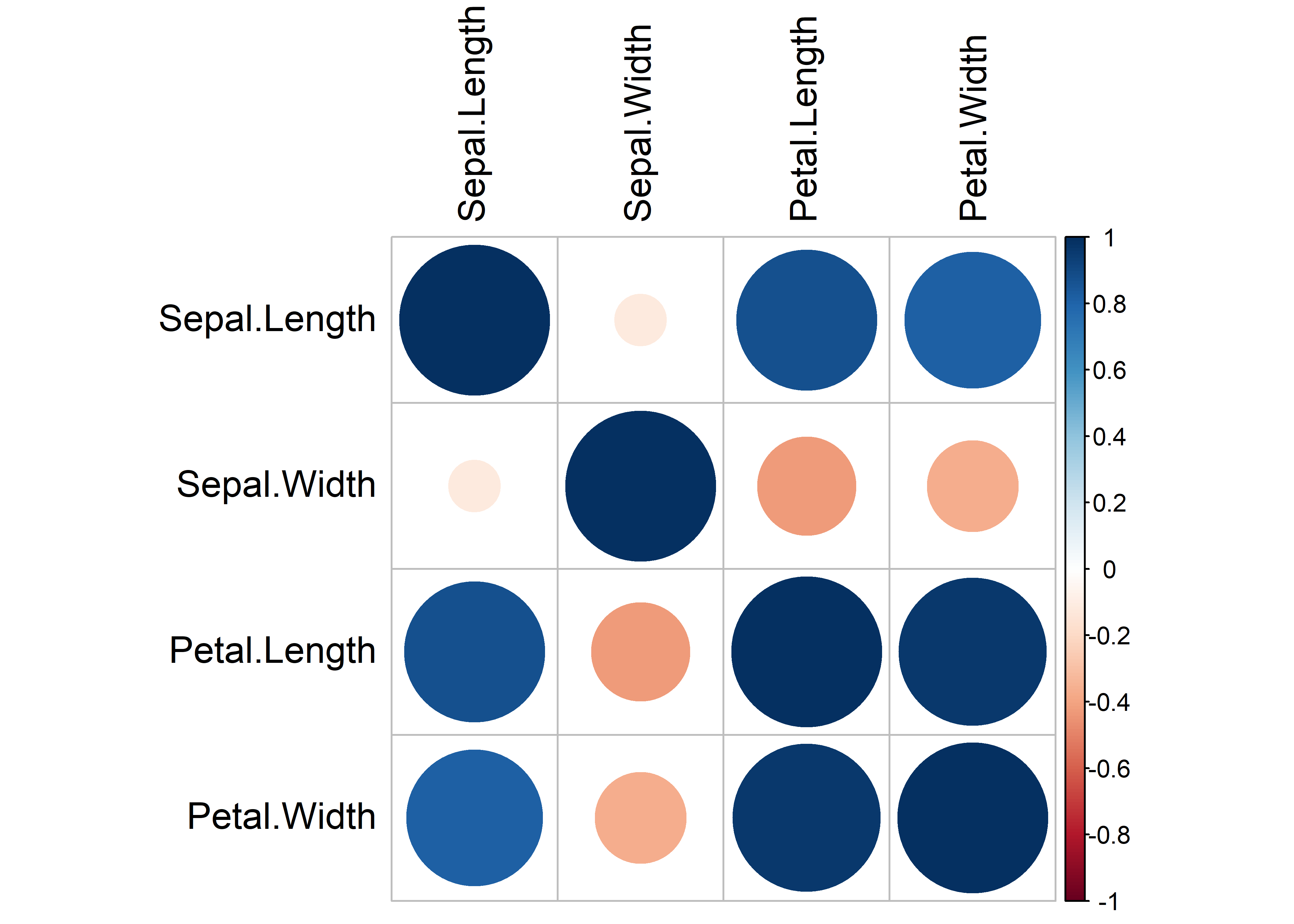
1.3. Opciones de visualización
corrplot ofrece siete tipos: 'circle', 'color', 'square', 'ellipse', 'number', 'shade', 'pie'. Aquí usamos 'color' con los coeficientes encima:
corrplot(matcor,
method = "color",
type = "lower",
order = "alphabet",
addCoef.col = "white",
number.digits = 2,
cl.pos = "b",
tl.col = "black",
tl.cex = 1.2,
number.cex = 0.9)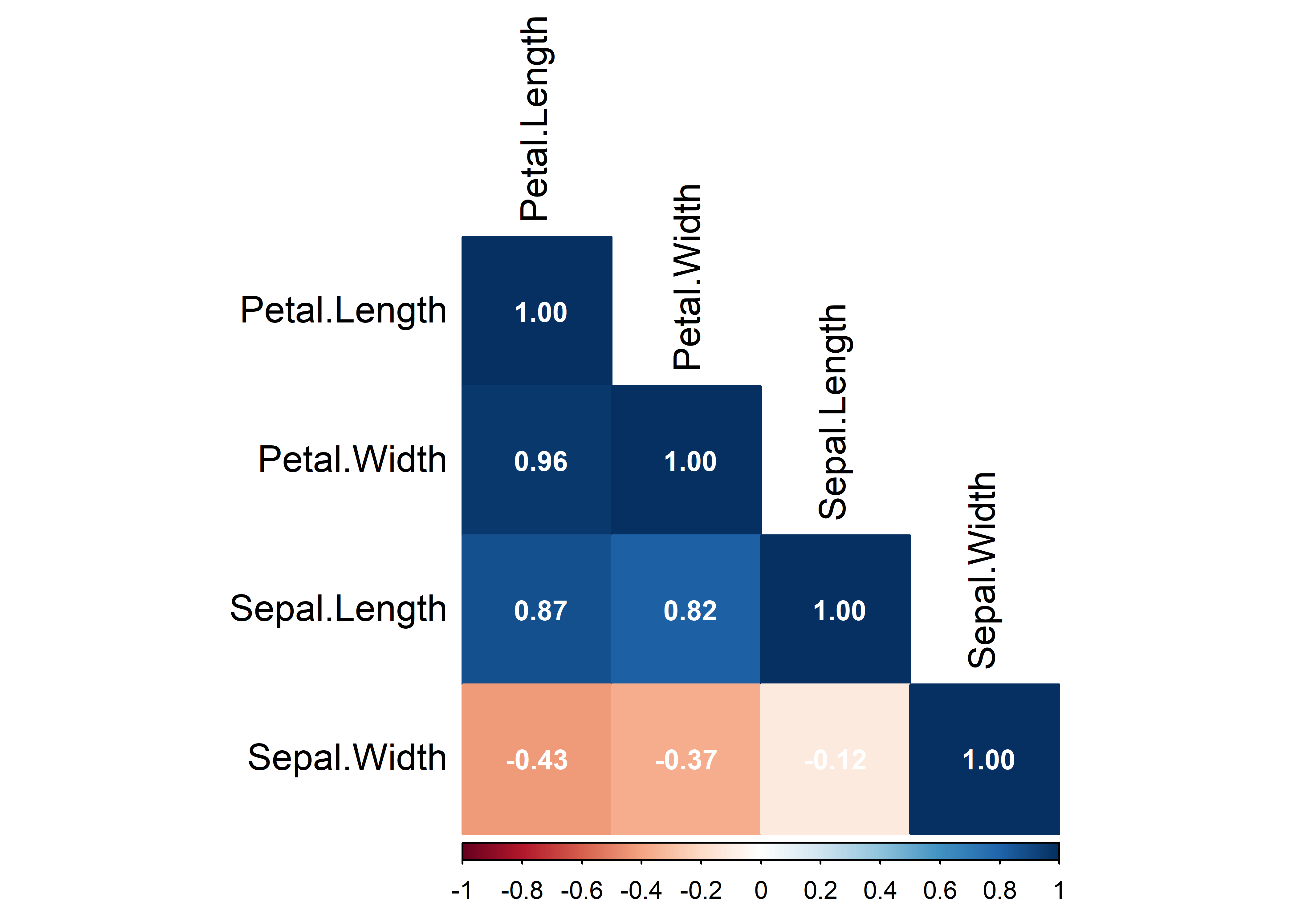
También podemos añadir las estrellas de significación:
testRes <- cor.mtest(matcor, conf.level = 0.95)
corrplot(matcor,
p.mat = testRes$p,
method = "circle",
type = "lower",
sig.level = c(0.001, 0.01, 0.05),
pch.cex = 0.9,
insig = "label_sig",
pch.col = "grey20",
col = brewer.pal(n = 8, name = "RdYlBu"),
cl.pos = "b",
tl.col = "black",
tl.cex = 1.2,
number.cex = 0.9)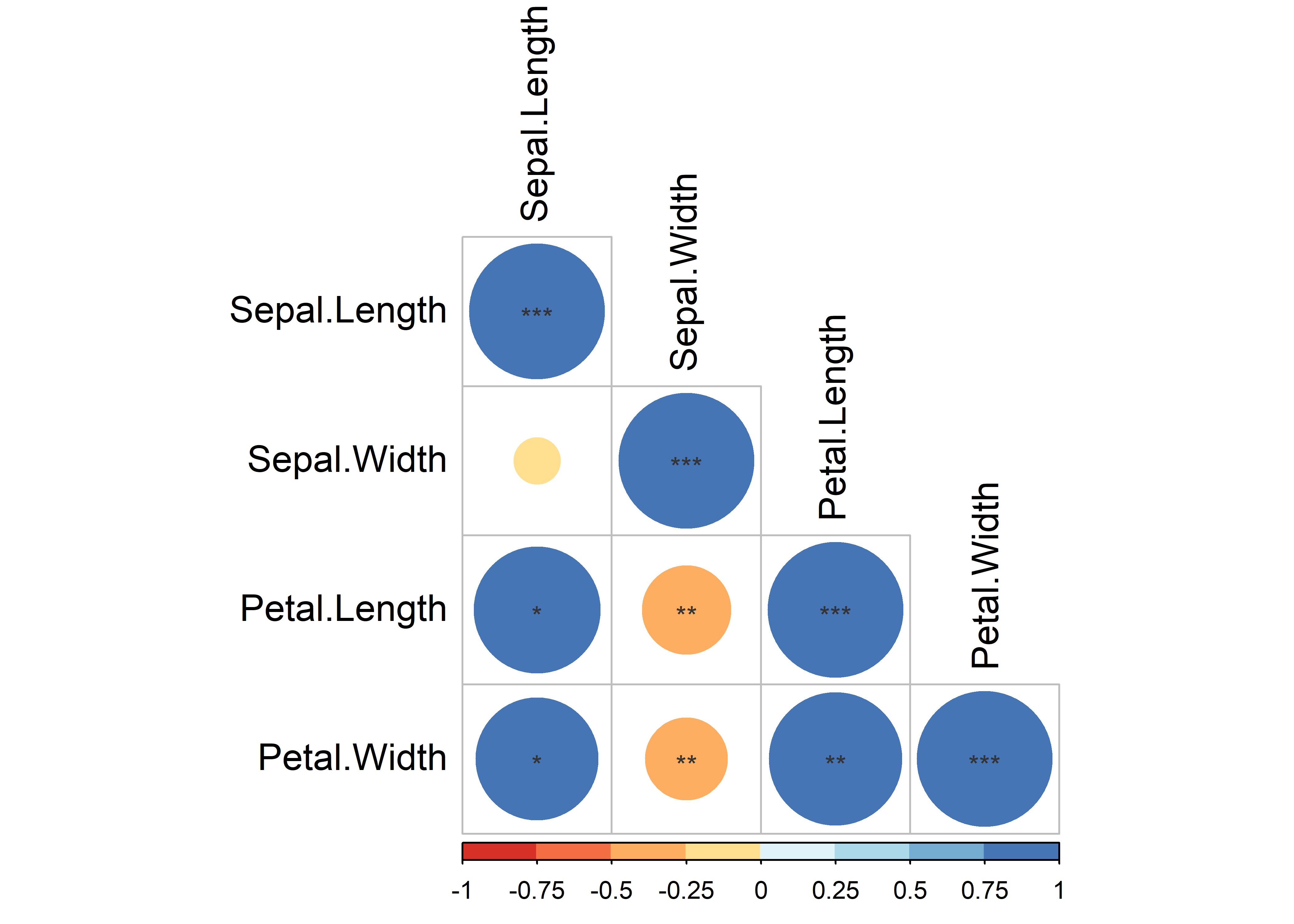
2. Comparación entre grupos
2.1. Preparar los datos
Calculamos media, desviación típica, error estándar e intervalos de confianza por grupo:
info <- datos4g %>%
group_by(group) %>%
summarise(
n = n(),
mean = mean(data_col),
sd = sd(data_col)
) %>%
mutate(
se = sd / sqrt(n),
ic = se * qt((1 - 0.05) / 2 + 0.5, n - 1)
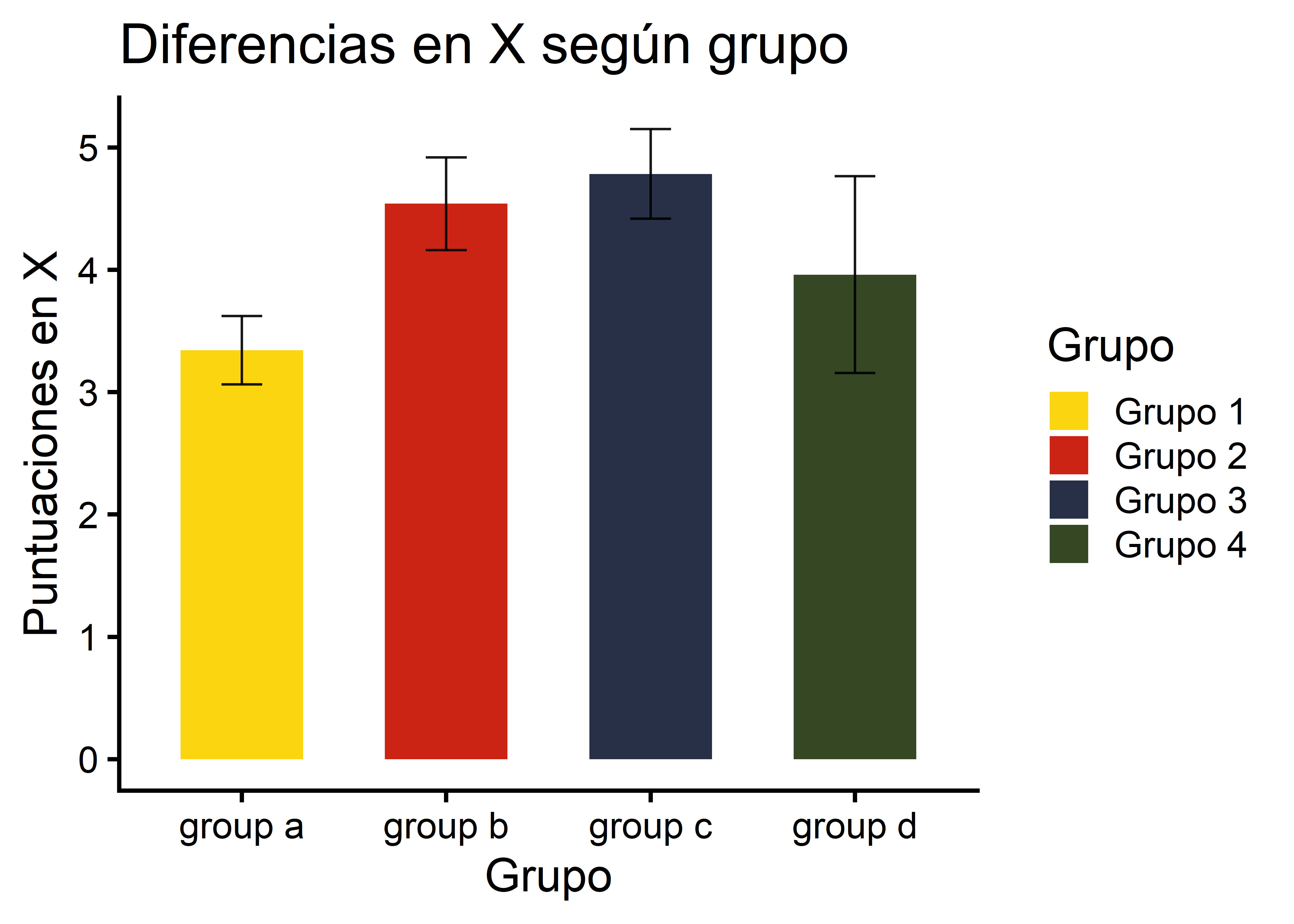
)2.2. Gráfico de barras con intervalos de confianza
ggplot(data = info, aes(x = group, y = mean, group = group, fill = group)) +
geom_col(alpha = 1, width = 0.6) +
geom_errorbar(aes(x = group, ymin = mean - ic, ymax = mean + ic),
width = 0.2, colour = "black", alpha = 0.9, linewidth = 0.5) +
ggtitle("Diferencias en X según grupo") +
xlab("Grupo") +
ylab("Puntuaciones en X") +
theme_classic(base_size = 18, base_family = "Roboto Condensed") +
scale_fill_manual(
name = "Grupo",
labels = c("Grupo 1", "Grupo 2", "Grupo 3", "Grupo 4"),
values = wes_palette("BottleRocket2")
)
2.3. Añadir significación estadística con ggsignif
geom_signif() marca automáticamente las comparaciones entre grupos indicadas:
grupos <- ggplot(data = info, aes(x = group, y = mean, group = group, fill = group)) +
geom_col(alpha = 1, width = 0.6) +
geom_errorbar(aes(x = group, ymin = mean - ic, ymax = mean + ic),
width = 0.2, colour = "black", alpha = 0.9, linewidth = 0.5) +
geom_signif(
comparisons = list(c("group a", "group b"),
c("group a", "group c"),
c("group a", "group d"),
c("group b", "group d"),
c("group c", "group d")),
map_signif_level = TRUE,
step_increase = 0.23
) +
ggtitle("Diferencias en X según grupo") +
ylab("Puntuaciones en X") +
theme_classic(base_size = 18, base_family = "Roboto Condensed") +
theme(axis.text.x = element_blank(),
axis.title.x = element_blank(),
axis.ticks.x = element_blank()) +
scale_fill_manual(
name = "Grupo",
labels = c("Grupo 1", "Grupo 2", "Grupo 3", "Grupo 4"),
values = wes_palette("BottleRocket2")
)
grupos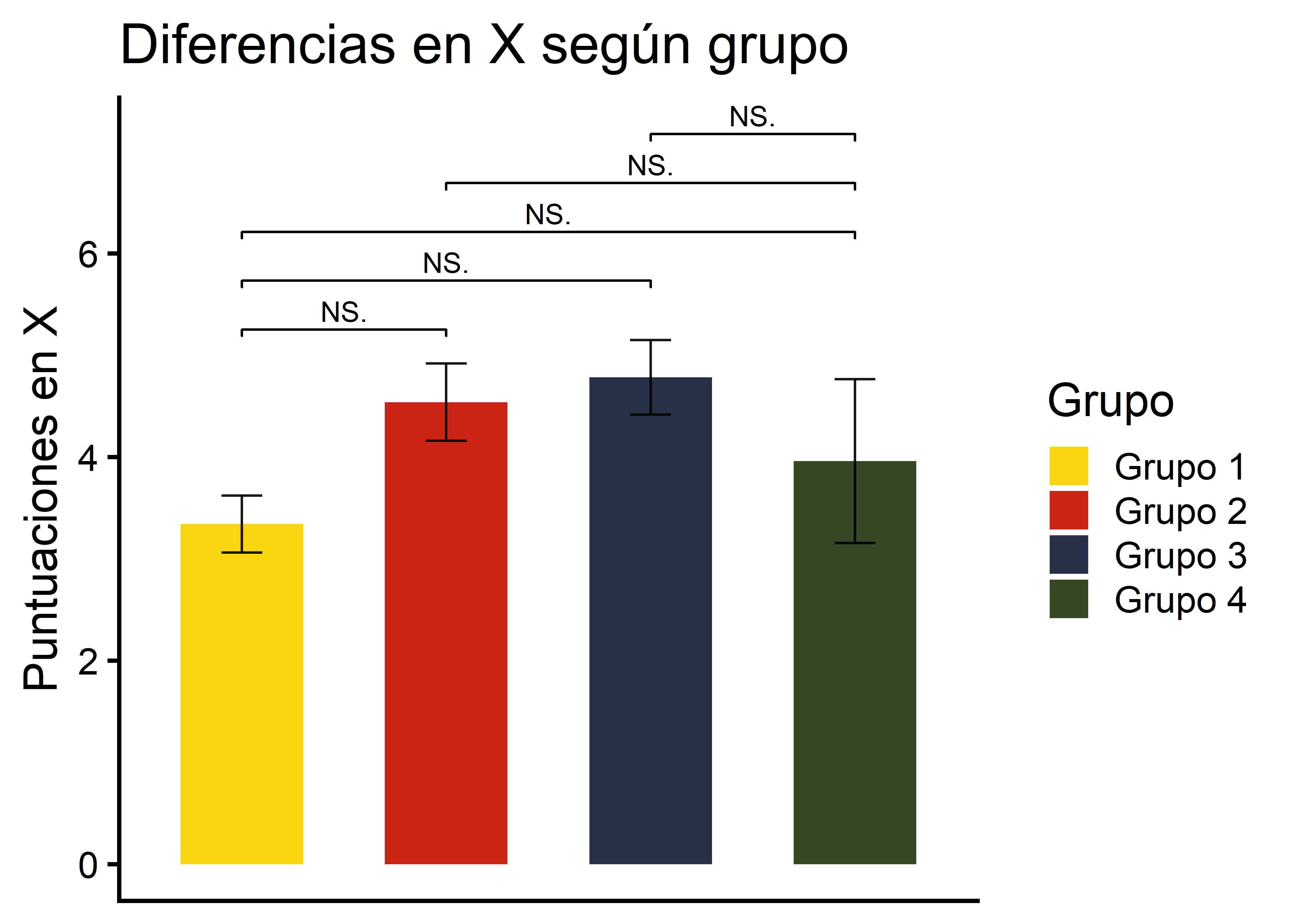
Hemos eliminado las etiquetas del eje x porque la leyenda ya hace ese trabajo. Eso se consigue con element_blank() en los tres argumentos de theme() que aparecen arriba.
ggsave("comparacion_grupos.png", plot = grupos,
width = 9, height = 6, dpi = 500)3. Violin plots
Los violin plots muestran la distribución completa de los datos, no solo la media. Son más informativos que las barras, especialmente cuando los grupos tienen formas asimétricas o bimodales.
3.1. Versión básica
violin1 <- ggplot(data = datos4g,
aes(x = group, y = data_col, group = group, fill = group)) +
geom_violin(trim = TRUE) +
geom_boxplot(width = 0.1, color = "black", alpha = 0.5) +
ggtitle("Diferencias en X según grupo") +
xlab("Grupo") +
ylab("Puntuaciones en X") +
theme_classic(base_size = 18, base_family = "Roboto Condensed") +
theme(axis.text.x = element_text(face = "bold"),
axis.ticks.x = element_blank(),
legend.position = "none") +
scale_fill_manual(values = wes_palette("GrandBudapest1")) +
scale_x_discrete(labels = c("Grupo 1", "Grupo 2", "Grupo 3", "Grupo 4"))
violin1
3.2. Versión avanzada: half-eye + boxplot + puntos
Una alternativa más informativa combina la distribución (con ggdist), un boxplot y los datos crudos en forma de puntos:
violin2 <- ggplot(datos4g, aes(x = group, y = data_col, fill = group)) +
ggdist::stat_halfeye(
adjust = 0.5,
width = 0.6,
.width = 0,
justification = -0.3,
point_colour = NA
) +
geom_boxplot(
width = 0.20,
alpha = 0.5,
outlier.shape = NA
) +
geom_point(aes(colour = group),
size = 2,
alpha = 0.7,
position = position_jitter(seed = 1, width = 0.1)
) +
coord_cartesian(xlim = c(1.2, NA), clip = "off") +
ggtitle("Diferencias en X según grupo") +
xlab("Grupo") +
ylab("Puntuaciones en X") +
theme_classic(base_size = 18, base_family = "Roboto Condensed") +
theme(axis.text.x = element_text(face = "bold"),
axis.ticks.x = element_blank(),
legend.position = "none") +
scale_x_discrete(labels = c("Grupo 1", "Grupo 2", "Grupo 3", "Grupo 4")) +
scale_fill_manual(values = wes_palette("GrandBudapest1")) +
scale_color_manual(values = wes_palette("GrandBudapest1"))
violin2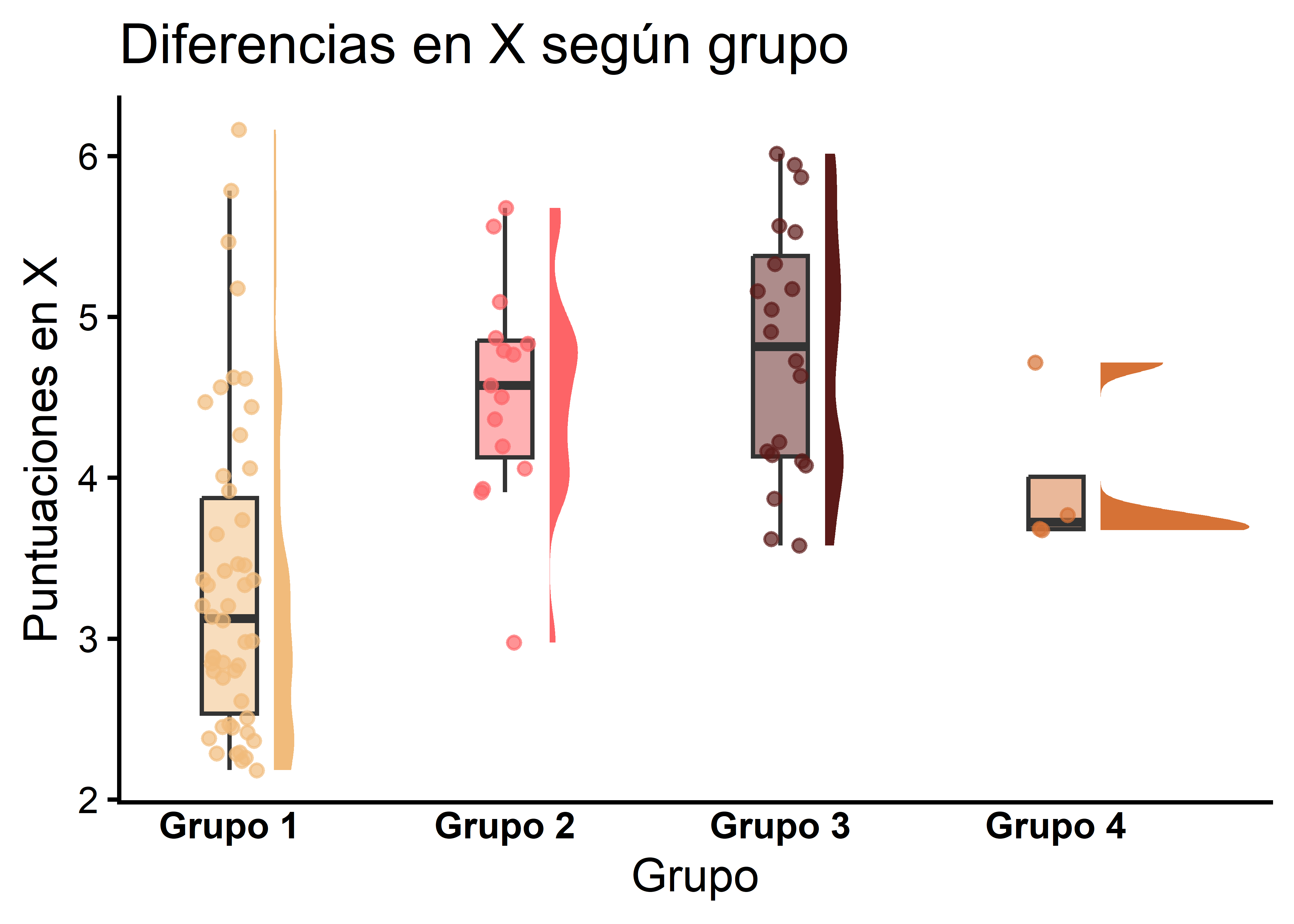
4. Combinar gráficos
Con ggarrange() del paquete ggpubr podemos unir varios gráficos en una sola figura:
figureviolin <- ggarrange(violin1, violin2, ncol = 2, nrow = 1)
figureviolin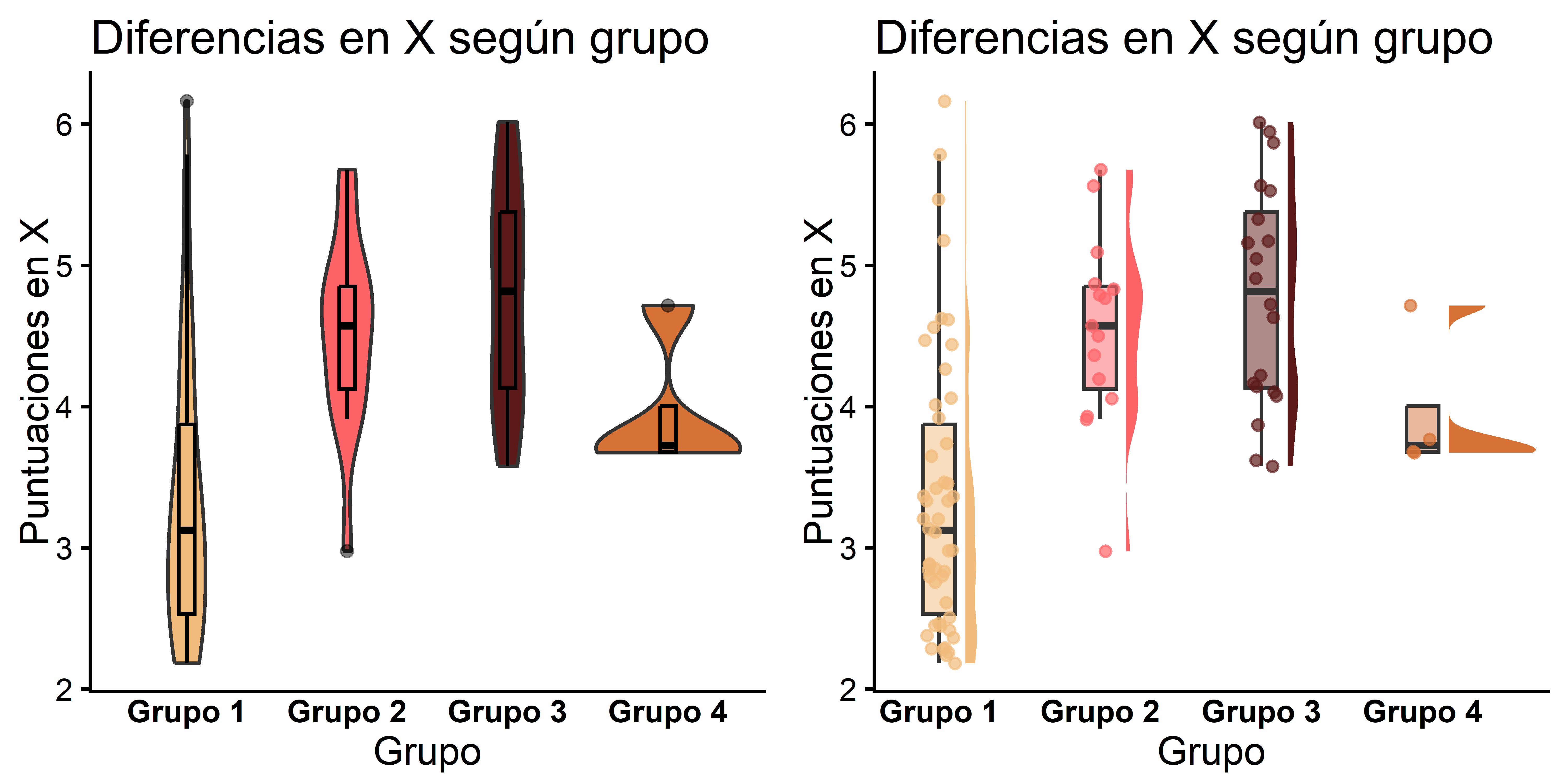
ggsave("violines.png", plot = figureviolin,
width = 10.5, height = 6, dpi = 500)5. Forest plots para meta-análisis
5.1. Los datos y el modelo
Creamos unos datos de ejemplo con siete estudios y calculamos los tamaños del efecto con el paquete metafor:
metadata <- tibble(
Estudio = paste("Estudio", 1:7),
mean1 = c(-0.178, -0.165, -0.12, -0.4, -0.31, -0.139, -0.017),
mean2 = c( 0.02, 0.03, 0.2, 0.1, 0.25, 0.22, 0.05),
sd1 = c( 0.5, 0.7, 0.78, 0.5, 0.8, 0.77, 0.61),
sd2 = c( 0.6, 0.5, 0.66, 0.72, 0.84, 0.67, 0.53),
n1 = c(250, 300, 25, 370, 119, 202, 400),
n2 = c(255, 278, 25, 370, 121, 204, 415)
)
resultado <- escalc(measure = "SMD",
m1i = mean1, m2i = mean2,
sd1i = sd1, sd2i = sd2,
n1i = n1, n2i = n2,
data = metadata)
res <- rma(yi, vi, data = resultado, method = "ML")5.2. Forest plot con ggplot2
Construimos la base de datos del gráfico a partir del modelo:
datam <- data.frame(
Estudio = c("Modelo", "Estudio 7", "Estudio 6", "Estudio 5",
"Estudio 4", "Estudio 3", "Estudio 2", "Estudio 1"),
Efecto = c(res$beta,
resultado[7, 8], resultado[6, 8], resultado[5, 8],
resultado[4, 8], resultado[3, 8], resultado[2, 8], resultado[1, 8]),
CI_L = c(res$ci.lb, -0.25, -0.69, -0.94, -0.96, -1.00, -0.48, -0.53),
CI_U = c(res$ci.ub, 0.02, -0.30, -0.42, -0.66, 0.12, -0.15, -0.18)
)
datam <- datam %>%
mutate(Estudio = factor(Estudio,
levels = c("Modelo", "Estudio 7", "Estudio 6",
"Estudio 5", "Estudio 4", "Estudio 3",
"Estudio 2", "Estudio 1")))metaplot <- ggplot(data = datam,
aes(y = Estudio, x = Efecto, xmin = CI_L, xmax = CI_U)) +
geom_point(color = "black", size = 5, shape = 15) +
geom_point(data = subset(datam, Estudio == "Modelo"),
color = "blue", fill = "blue", size = 10, shape = 23) +
geom_errorbarh(height = 0.3) +
geom_errorbarh(data = subset(datam, Estudio == "Modelo"),
color = "blue", height = 0.03) +
scale_x_continuous(limits = c(-1.5, 0.5), name = "Tamaño del efecto") +
geom_vline(xintercept = 0, color = "red", linetype = "dashed", alpha = 0.5) +
labs(title = "Meta-análisis",
subtitle = "Efecto estimado e IC 95% por estudio",
y = "") +
theme_minimal() +
theme(text = element_text(family = "Roboto Condensed", size = 18, color = "black"),
aspect.ratio = 201 / 200)
metaplot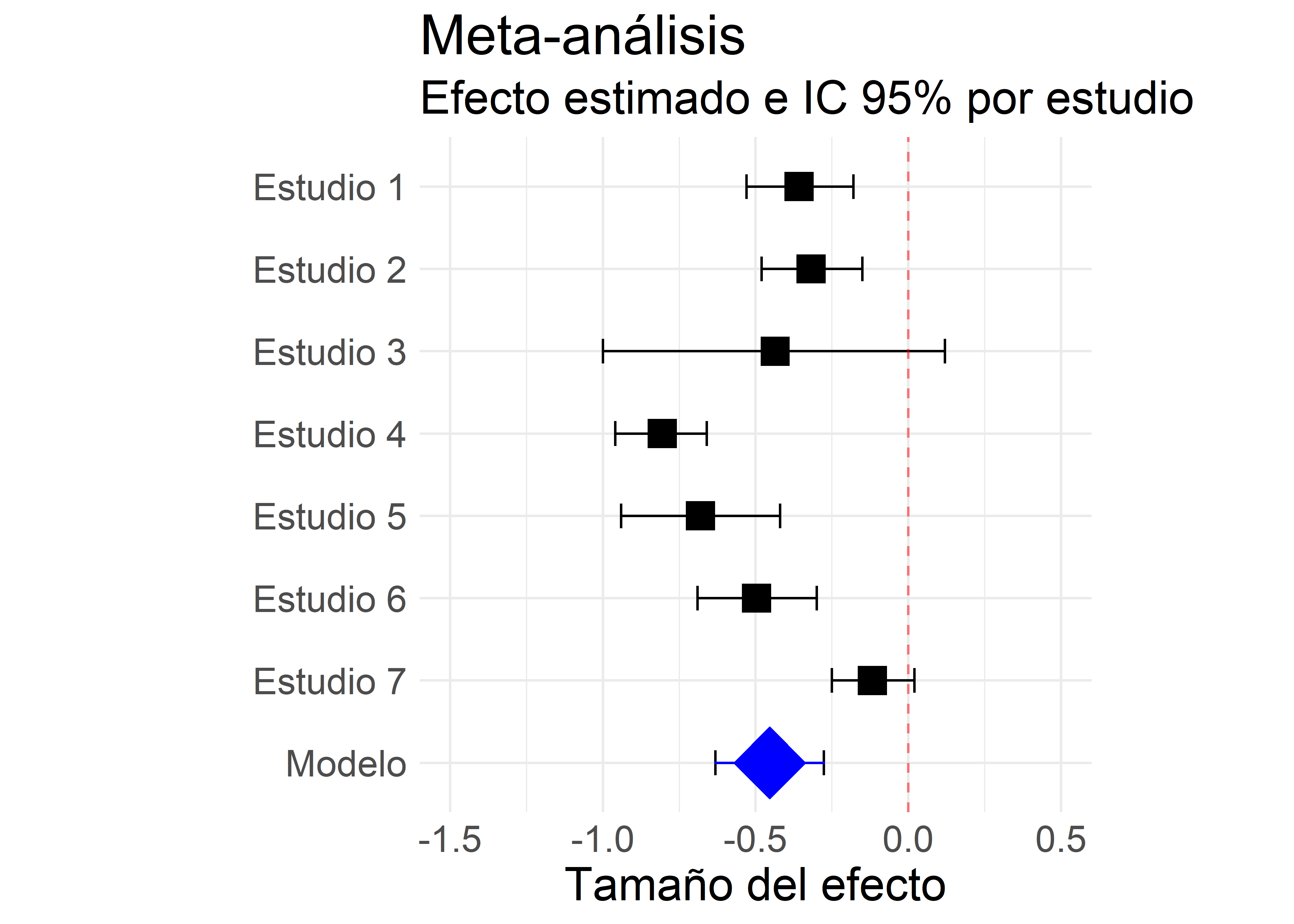
ggsave("forestplot.png", plot = metaplot,
width = 9, height = 6, dpi = 500)5.3. Alternativa rápida con el paquete forestplot
Para quien prefiere una solución más directa:
estrmeta <- structure(
list(
mean = c(NA, NA, 0.578, 0.165, 0.246, 0.700, 0.348, 0.139, 1.017, NA, 0.531),
lower = c(NA, NA, 0.372, 0.018, 0.072, 0.333, 0.083, 0.016, 0.365, NA, 0.386),
upper = c(NA, NA, 0.898, 1.517, 0.833, 1.474, 1.455, 1.209, 2.831, NA, 0.731)
),
.Names = c("mean", "lower", "upper"),
row.names = c(NA, -11L),
class = "data.frame"
)
tabletext <- cbind(
c("", "Estudio", "Auckland", "Block", "Doran", "Gamsu",
"Morrison", "Papageorgiou", "Tauesch", NA, "Resumen"),
c("Muertes", "(esteroides)", "36", "1", "4", "14", "3", "1", "8", NA, NA),
c("Muertes", "(placebo)", "60", "5", "11","20", "7", "7", "10", NA, NA),
c("", "OR", "0.58", "0.16", "0.25", "0.70", "0.35", "0.14", "1.02", NA, "0.53")
)
estrmeta |>
forestplot(
labeltext = tabletext,
is.summary = c(rep(TRUE, 2), rep(FALSE, 8), TRUE),
clip = c(0.1, 2.5),
xlog = TRUE,
col = fpColors(box = "royalblue", line = "darkblue", summary = "royalblue")
)
6. Gráficos interactivos con plotly
Cualquier gráfico de ggplot2 puede convertirse en interactivo con una sola función: ggplotly(). El usuario podrá hacer zoom, desplazarse y ver los valores al pasar el cursor.
library(faux)
set.seed(1)
datoscor <- rnorm_multi(n = 3000, mu = c(7, 7, 7), sd = c(0.9, 1.2, 0.71),
r = c(0.5, 0, -0.7), varnames = c("x", "y", "z"))
corplot <- ggplot(data = datoscor, aes(x = x, y = z)) +
geom_point(alpha = 0.2) +
geom_smooth(method = lm, color = "red", fill = "blue", se = TRUE) +
labs(title = "Relación entre leer y ser tolerante",
subtitle = "Ni leyendo ni viajando") +
theme_classic(base_size = 18, base_family = "Roboto Condensed") +
ylab("Libros") + xlab("Tolerancia") +
scale_x_continuous(limits = c(3, 10)) +
scale_y_continuous(limits = c(3, 10))ggplotly(corplot)saveWidget(as_widget(ggplotly(corplot)), "grafico_interactivo.html")Con esto concluyen los dos volúmenes. La idea no es que memorices cada función, sino que tengas un repertorio de ejemplos a los que volver cuando necesites un tipo concreto de gráfico. El paso que más aprende es el de experimentar: cambia un argumento, ve qué pasa, y en algún momento el gráfico empieza a responder exactamente como quieres.